What is Embedding (AI)?
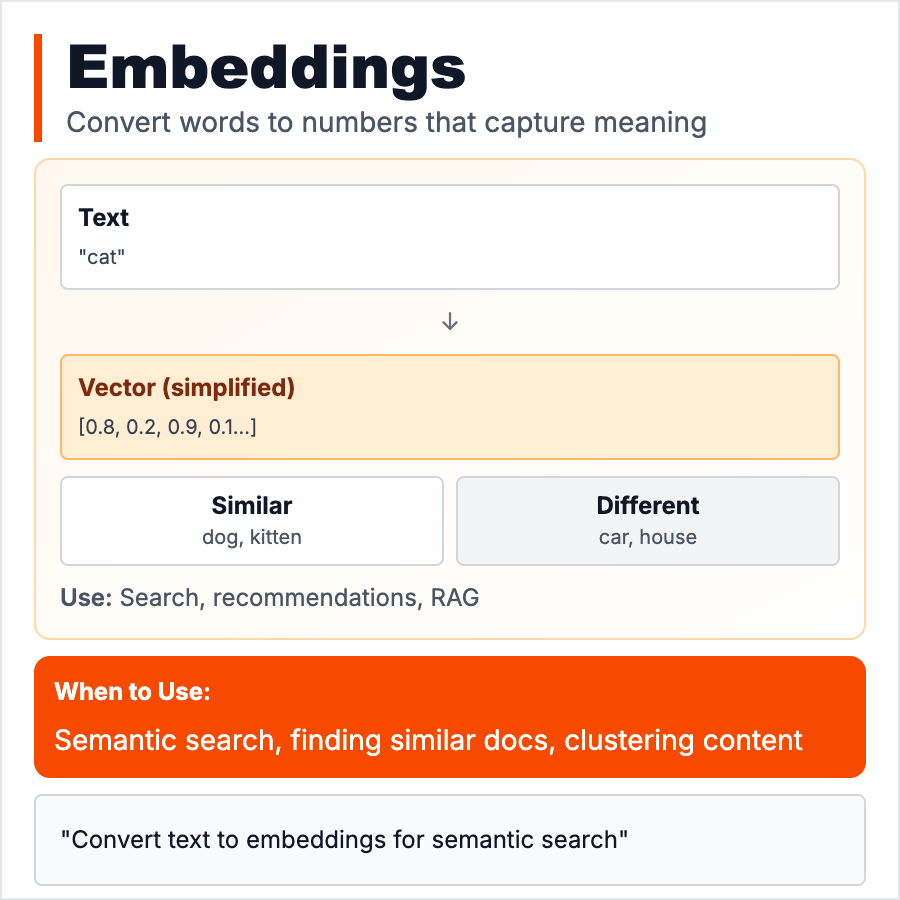
Embeddings convert text (or images, audio) into arrays of numbers (vectors) that capture meaning. "King" and "Queen" have similar embeddings (both royalty). "King" and "Pizza" are far apart. Lets computers understand semantic similarity. Used for: search (find similar docs), recommendations (similar products), RAG (find relevant context), clustering (group similar items). Generated by models like OpenAI ada-002, Cohere. Store in vector databases.
When Should You Use This?
Use embeddings for: semantic search (search by meaning not keywords), RAG systems (find relevant docs), recommendations (similar items), clustering/classification (group by meaning), or duplicate detection. Generate once, store in vector DB, search fast. Essential for any AI feature that needs to "find similar" items. OpenAI charges ~$0.0001 per 1K tokens to generate embeddings.
Common Mistakes to Avoid
- •Using keyword search—embeddings capture meaning, better than exact match
- •Not normalizing—normalize vectors for accurate similarity scores
- •Wrong model—use domain-specific embedding model for technical/medical content
- •Not caching—embeddings are expensive to generate, cache them
- •Comparing across models—embeddings from different models aren't compatible
Real-World Examples
- •Search—User searches "refund policy" → find docs with similar meaning (even if worded differently)
- •RAG—Embed user question + all KB articles → find most similar articles → feed to AI
- •Recommendations—Embed products → find similar products based on description similarity
- •Duplicate detection—Embed support tickets → find similar past tickets
Category
Ai Vocabulary